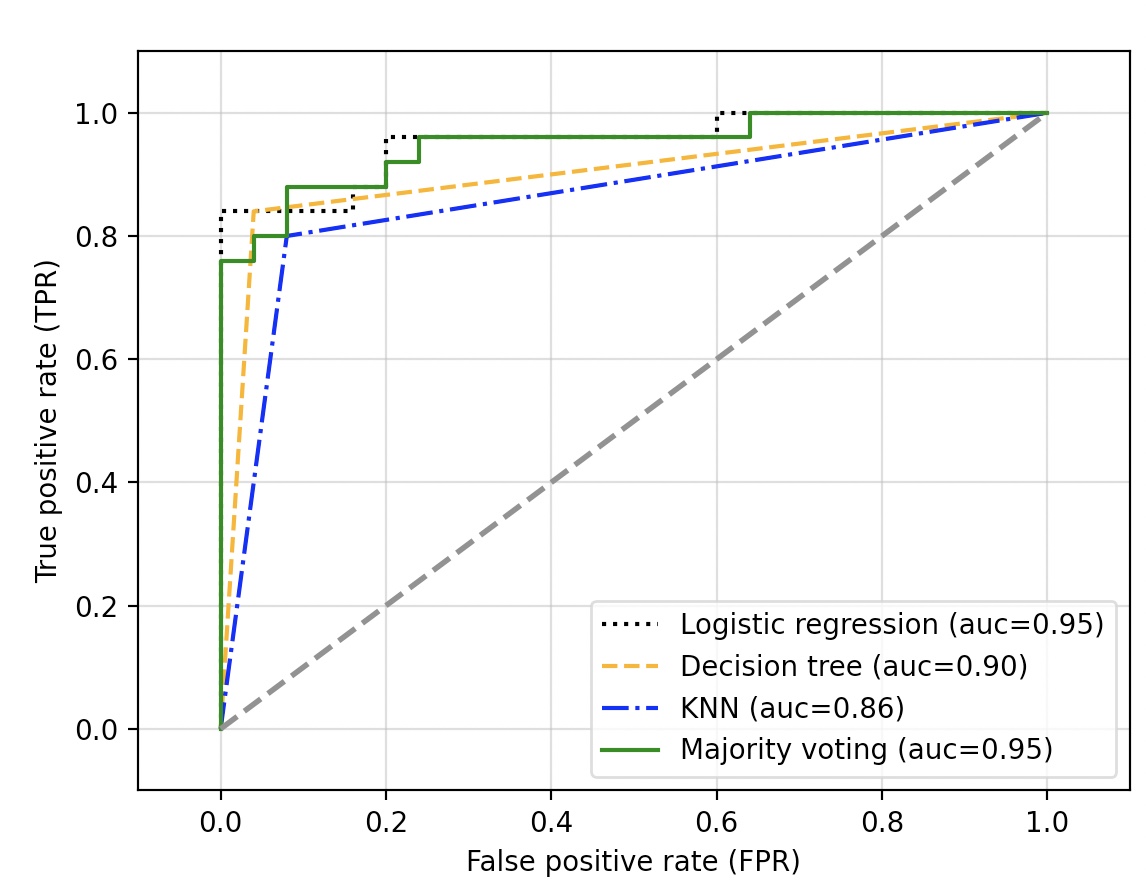
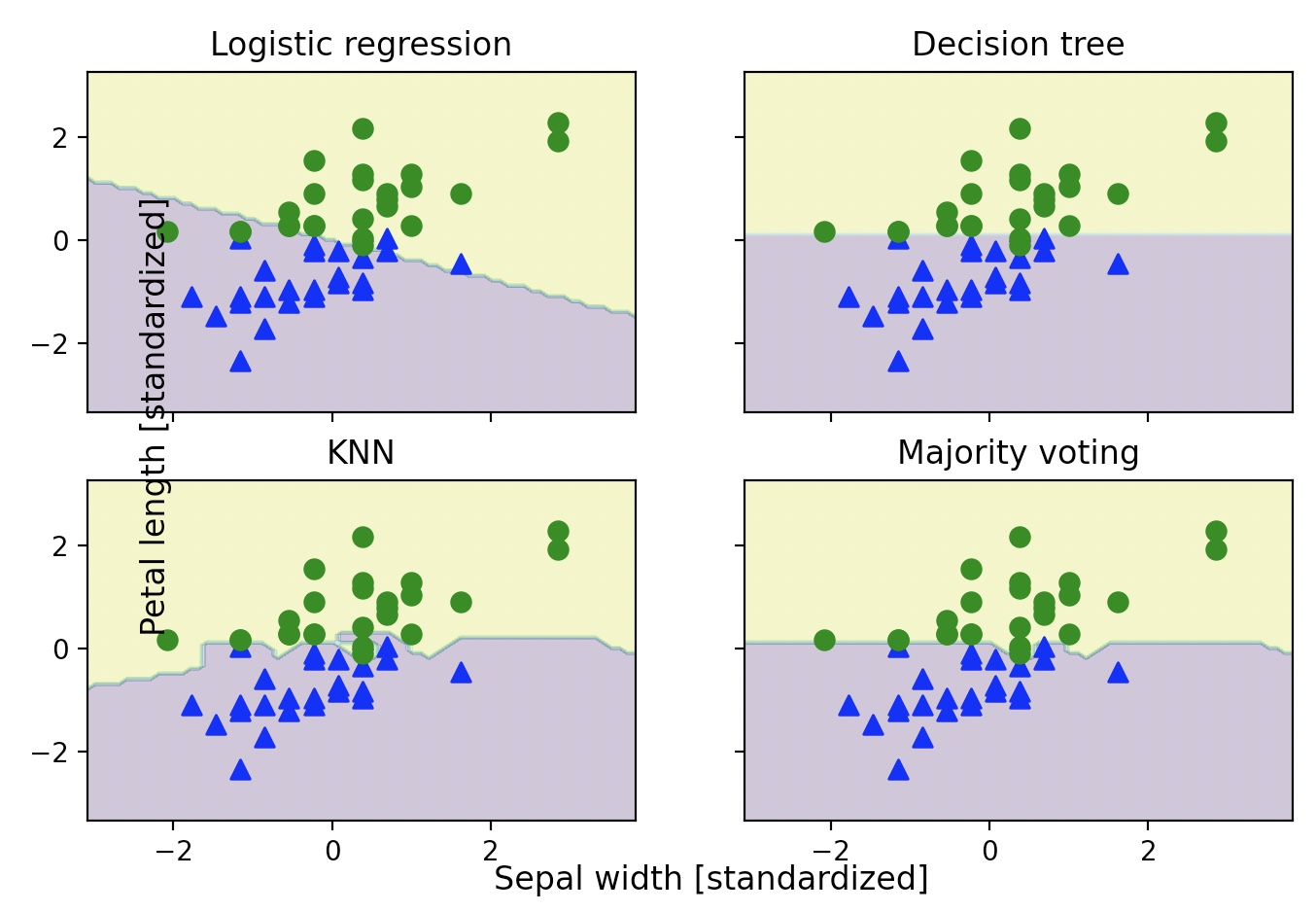
{'pipeline-1': Pipeline(steps=[('sc', StandardScaler()),
['clf', LogisticRegression(C=0.001, random_state=1)]]), 'decisiontreeclassifier': DecisionTreeClassifier(criterion='entropy', max_depth=1, random_state=0), 'pipeline-2': Pipeline(steps=[('sc', StandardScaler()),
['clf', KNeighborsClassifier(n_neighbors=1)]]), 'pipeline-1__memory': None, 'pipeline-1__steps': [('sc', StandardScaler()), ['clf', LogisticRegression(C=0.001, random_state=1)]], 'pipeline-1__verbose': False, 'pipeline-1__sc': StandardScaler(), 'pipeline-1__clf': LogisticRegression(C=0.001, random_state=1), 'pipeline-1__sc__copy': True, 'pipeline-1__sc__with_mean': True, 'pipeline-1__sc__with_std': True, 'pipeline-1__clf__C': 0.001, 'pipeline-1__clf__class_weight': None, 'pipeline-1__clf__dual': False, 'pipeline-1__clf__fit_intercept': True, 'pipeline-1__clf__intercept_scaling': 1, 'pipeline-1__clf__l1_ratio': None, 'pipeline-1__clf__max_iter': 100, 'pipeline-1__clf__multi_class': 'auto', 'pipeline-1__clf__n_jobs': None, 'pipeline-1__clf__penalty': 'l2', 'pipeline-1__clf__random_state': 1, 'pipeline-1__clf__solver': 'lbfgs', 'pipeline-1__clf__tol': 0.0001, 'pipeline-1__clf__verbose': 0, 'pipeline-1__clf__warm_start': False, 'decisiontreeclassifier__ccp_alpha': 0.0, 'decisiontreeclassifier__class_weight': None, 'decisiontreeclassifier__criterion': 'entropy', 'decisiontreeclassifier__max_depth': 1, 'decisiontreeclassifier__max_features': None, 'decisiontreeclassifier__max_leaf_nodes': None, 'decisiontreeclassifier__min_impurity_decrease': 0.0, 'decisiontreeclassifier__min_impurity_split': None, 'decisiontreeclassifier__min_samples_leaf': 1, 'decisiontreeclassifier__min_samples_split': 2, 'decisiontreeclassifier__min_weight_fraction_leaf': 0.0, 'decisiontreeclassifier__random_state': 0, 'decisiontreeclassifier__splitter': 'best', 'pipeline-2__memory': None, 'pipeline-2__steps': [('sc', StandardScaler()), ['clf', KNeighborsClassifier(n_neighbors=1)]], 'pipeline-2__verbose': False, 'pipeline-2__sc': StandardScaler(), 'pipeline-2__clf': KNeighborsClassifier(n_neighbors=1), 'pipeline-2__sc__copy': True, 'pipeline-2__sc__with_mean': True, 'pipeline-2__sc__with_std': True, 'pipeline-2__clf__algorithm': 'auto', 'pipeline-2__clf__leaf_size': 30, 'pipeline-2__clf__metric': 'minkowski', 'pipeline-2__clf__metric_params': None, 'pipeline-2__clf__n_jobs': None, 'pipeline-2__clf__n_neighbors': 1, 'pipeline-2__clf__p': 2, 'pipeline-2__clf__weights': 'uniform'}
0.950 +/- 0.07 {'dt__max_depth': 1, 'lr__clf__C': 0.001}
0.983 +/- 0.02 {'dt__max_depth': 1, 'lr__clf__C': 0.1}
0.967 +/- 0.05 {'dt__max_depth': 1, 'lr__clf__C': 100.0}
0.950 +/- 0.07 {'dt__max_depth': 2, 'lr__clf__C': 0.001}
0.983 +/- 0.02 {'dt__max_depth': 2, 'lr__clf__C': 0.1}
0.967 +/- 0.05 {'dt__max_depth': 2, 'lr__clf__C': 100.0}